内存管理
分层存储器体系
存储管理器:操作系中管理分层存储器体系的部分,用来记录哪些内存正在使用,哪些内存空闲
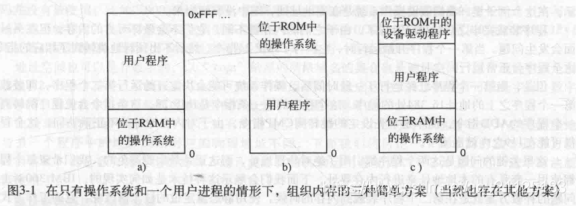
无存储器抽象
IBM 360系统的不用交换运行多个程序,其通过对地址进行一个静态映射,来达到一个逻辑地址与物理地址的分离
存储器抽象:地址空间
将物理地址直接暴露给进程,除非硬件能给予特殊的保护,否则进程可以任意对整个内存进行读写操作,不论有意无意,这是很危险的。另外一个问题就是这种抽象很难实现多道程序设计。
概念
所谓地址空间,就是一系列地址集合(内存地址0...内存地址n),而独立的地址空间则代表每个进程都有属于自己的地址空间,类似于编程语言中的命名空间,不同的命名空间下,可以有同名的标志符
运行多个程序互相不影响,需要解决两问题:
- 保护不属于该进程的内存
- 重定位
内存重定位可以通过两个寄存器来实现:
- 基址寄存器
- 界限寄存器
相当于划定一个物理内存范围,进程的内存就分配在此区域之内,并且操作系统对内存地址做一次重定位
交换技术
把一个进程从磁盘完整调入内存,使该进程运行一段时间,再将其的内存写回磁盘
内存紧缩:将小空闲区合并成一大块
当频繁进行内存交换,内存就会之间就会出现空洞,就需要使用内存紧缩,确保能有较大的一片连续内存区域给后续内存分配
空闲内存管理
操作系统需要管理分配的动态内存
使用位图的存储管理
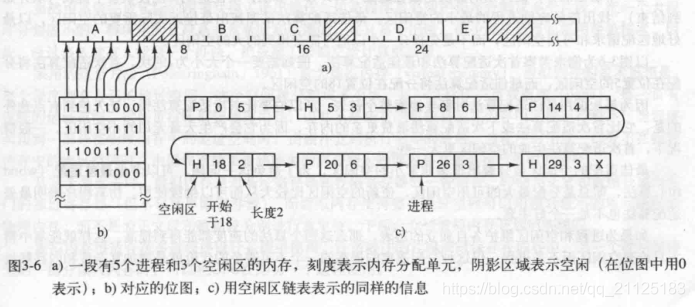
通过一个bitmap的槽为0还是为1,代表某一块内存是否为空闲
当每一块内存单元越小,所需要的位图就需要越大,分配一整块大小为n连续的内存时,就需要搜索到连续出现了n个0的内存块
使用链表
通过将不连续的内存块用链表连接起来
使用链表的内存分配算法:
- 首次适配算法:找到一个比所需内存大或者刚好等于的内存块,将其分配给进程,余下的内存加会到链表
- 下次适配算法:首次适配每次都从头找,而下次适配则从上次找到的地方开始找
- 最佳适配算法:找出最接近所需的内存的一个内存块,需要搜索整个链表
- 最差适配算法:每次都选择最大的一块空间
- 快速适配算法:维护常用大小的内存空间,4k 16k 之类的,这样就能快速分配
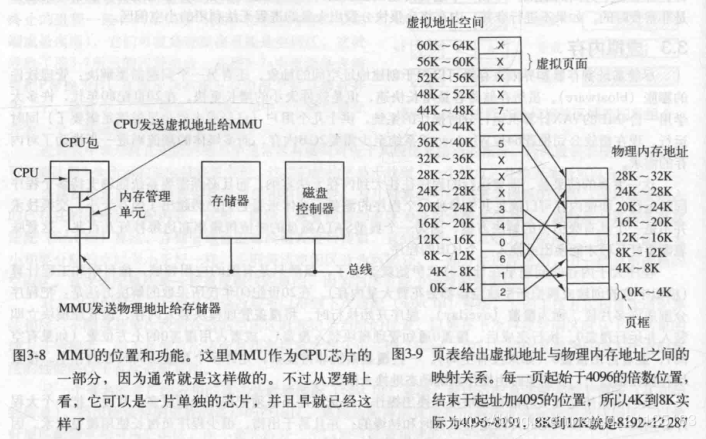
虚拟内存
地址空间被分为多块,每块称作页 页被映射到物理内存,如果程序引用不存在的物理内存 由操作系统负责将缺失的部分装入物理内存
分页
当虚拟地址空间是比物理地址空间大时,当程序请求一个不存在物理地址的虚拟地址时,MMU通过缺页中断:当访问的页没有映射到物理内存中时,操作系统会将其他的页写到磁盘,将空出来的内存映射给当前的页,内存管理单元(MMU) 则是执行这个映射的服务
页表
页表项的结构:
- 保护位:允许什么类型的访问(读、写、执行)
- 修改位:判断页面是否被写过
- 访问位:判断页面是否被访问过
- 高速缓存禁止位
加速分页过程
分页系统需要考虑的2个问题:
- 虚拟地址映射到物理地址必须非常快
- 如果虚拟地址空间很大,则页表也会很大
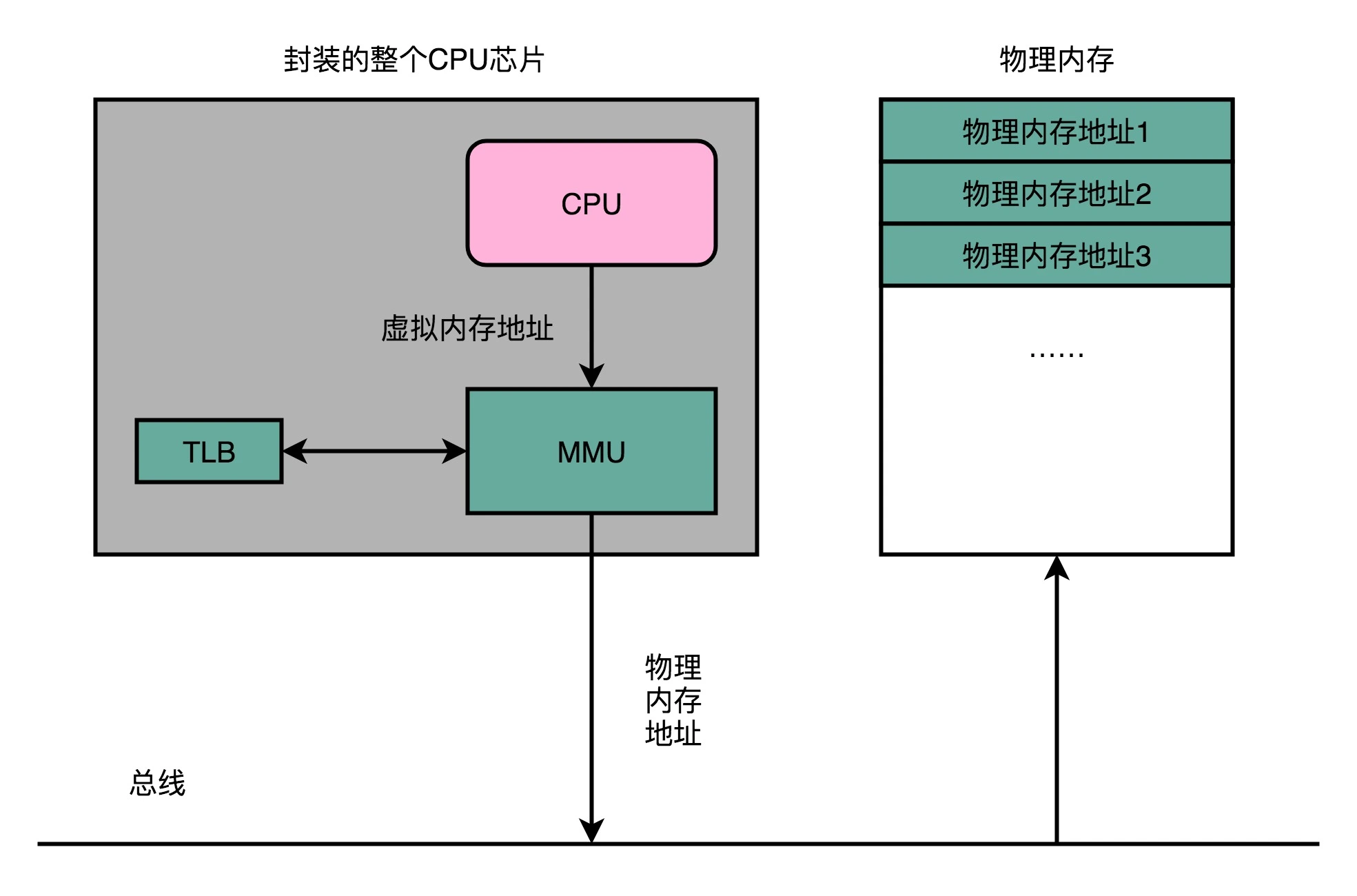
TLB
转换检测缓冲区(TLB):小型硬件设备,本质就是个缓存,其可以通过并行的方式对虚拟地址进行查找,如果在缓冲区中命中,就直接返回,否则再去查找页表,是一种多级缓存架构
缓存存放了之前已经进行过地址转换的查询结果。这样,当同样的虚拟地址需要进行地址转换的时候,我们可以直接在 TLB 里面查询结果,而不需要多次访问内存来完成一次转换
软件TLB管理
- 软失效:页表不在TLB里,但在内存中,需要少量的代价更新TLB
- 硬失效:页表也不在内存里,需要读取磁盘
针对大内存的页表
多级页表
进行两次查找
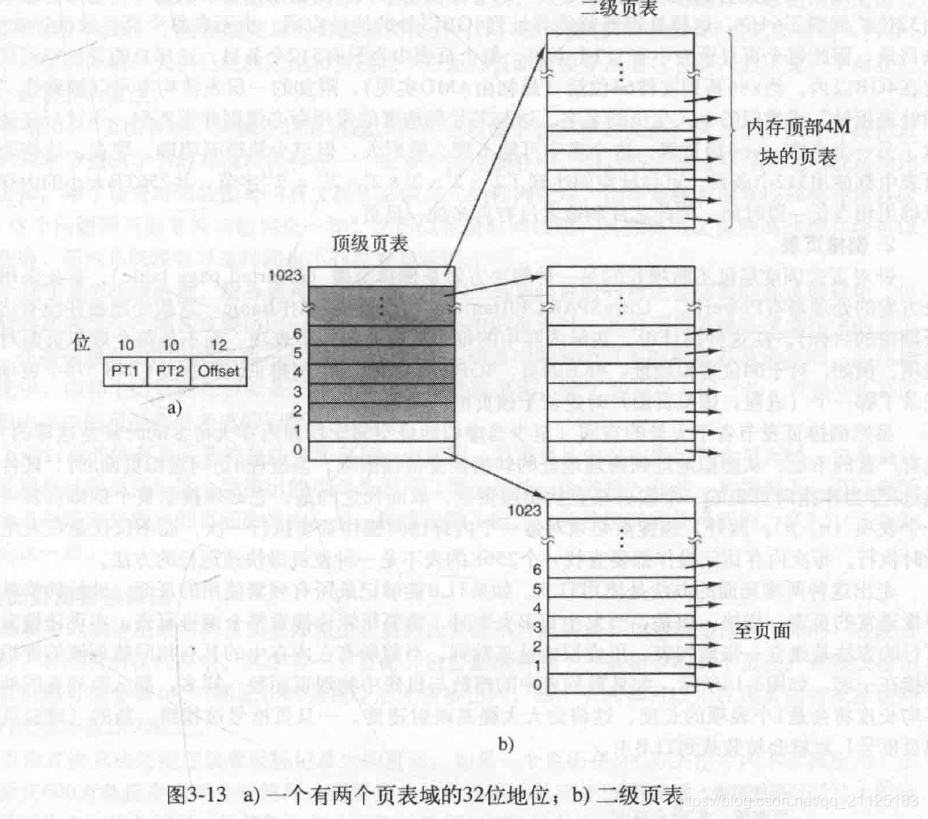
多级页表由于二级三级项在没被使用的时候可以不创建,且二级三级项甚至可以不存在内存中,所以可以减少内存的使用
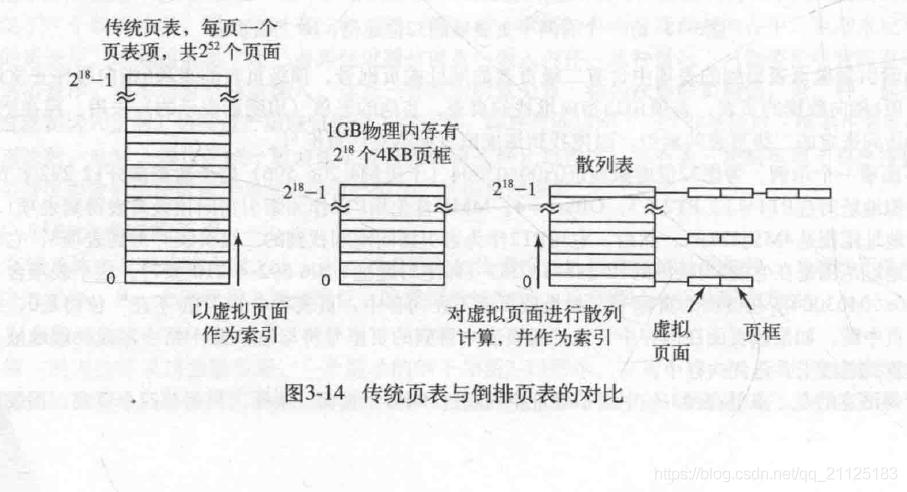
倒排页表
需要使用TLB作为前置缓存,当TLB搜索不到,需要查找整个页表来找到所需的页表
为了避免对整个页表的搜索,可以使用对虚拟地址进行散列,使用散列值使用常数时间复杂度找到需要的页表
页面置换算法
主要目的:挑选出最不常使用的页面,本质就是缓存的淘汰
| 算法 | 注释 |
|---|---|
| 最优算法 | 不可实现,但可用作基准 |
| NRU (最近未使用)算法 | LRU的很粗糙的近似 |
| FIFO (先进先出)算法 | 可能抛弃重要页面 |
| 第二次机会算法 | 比FIFO有较大的改善 |
| 时钟算法 | 现实的 |
| LRU (最近最少使用)算法 | 很优秀,但很难实现 |
| NFU (最不经常使用)算法 | LRU的相对粗略的近似 |
| 老化算法 | 非常近似LRU的有效算法 |
| 工作集算法 | 实现起来开销很大 |
| 工作集时钟算法 | 好的有效算法 |
最优页面置换算法(OPT, Optimal replacement algorithm)
无法确定哪个页面未来最少被使用 ,该算法只是一种理论算法,无法实现
最近未使用(NRU)页面置换算法
随机淘汰最近一个时钟周期没有访问、没有修改的最老的页面
先进先出页面置换算法(FIFO, First In First Out)
选择换出的页面是最老的页面
第二次机会页面置换算法
淘汰掉一个进入时间最长,且最久未被使用的页面
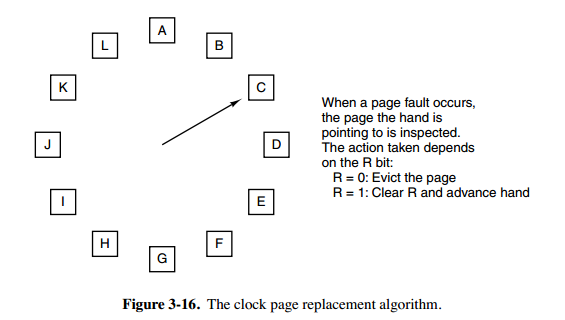
时钟页面置换算法
使用一个指针指向最老的页面,当需要淘汰页面时,如果这个页面R标志位为0,则淘汰的就是这个页面
如果这个页面被修改过,则将R标志位设置为0,然后向前移动指针,直到找到一个R标志位0的页面,淘汰它
淘汰完页面,新的页面插入到被淘汰的这个位置
最近最少使用(LRU)页面置换算法
- 这种方式在缓存系统中经常被使用
在内存中维护一个所有页面的链表。当一个页面被访问时,将这个页面移到链表表头。这样就能保证链表表尾的页面是最近最久未访问的
另外一种实现方式则是对于每个页表项维护一个计数器,这个计数器会随着系统的运行时间增加而增加,要淘汰的时候就遍历整个链表,找到计数器最小的页表项
两种方式都可以配合哈希表可以实现 O(1) 时间复杂度的查找及删除,只是二者维护访问状态的方式不同,一种对应实现的数据结构就是LinkedHashMap
用软件模拟LRU
最不常使用(NFU) 会记住最近一段时间内各个时钟周期的访问情况
工作集页面置换算法
工作集:进程当前正在使用的页面集合 淘汰掉工作集中最少使用的页面
工作集时钟页面置换算法
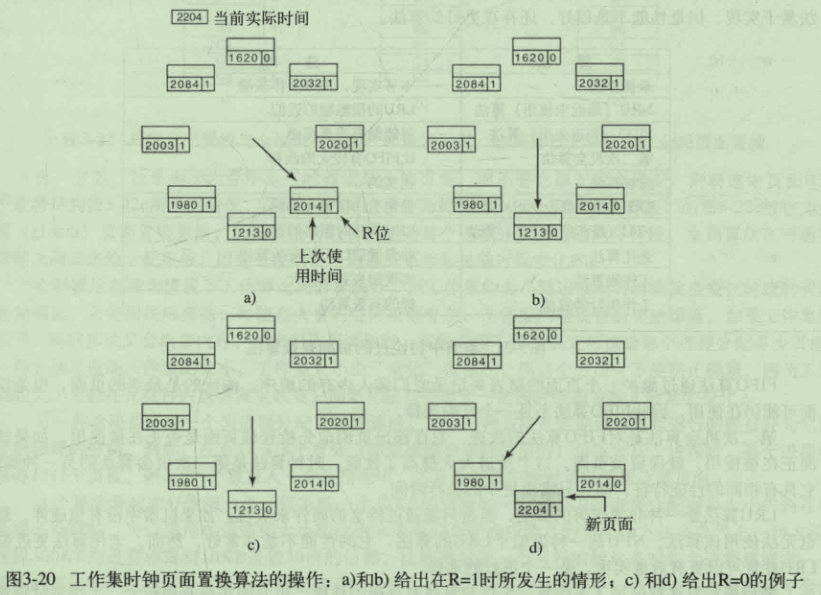
分页系统中的设计问题
局部分配策略与全局分配策略
缺页中断率(PFF):用来指出何时增加或减少分配给进程的页面,中断率越高的进程需要更多的页面,以避免内存颠簸
负载控制
当所有进程所需的内存总量超出了物理内存总量时,则需要交换一部分进程到磁盘中,避免大量的缺页中断带来的系统颠簸
页面大小
大页面带来的问题就是如果需要大量的小内存,则大页面里面就会需要内存碎片。
选择小页面的好处在于可以有效利用内存,但同时更小的页面意味着需要更多的页表。
现在常见的页面大小事4K和8K
分离的指令空间和数据空间
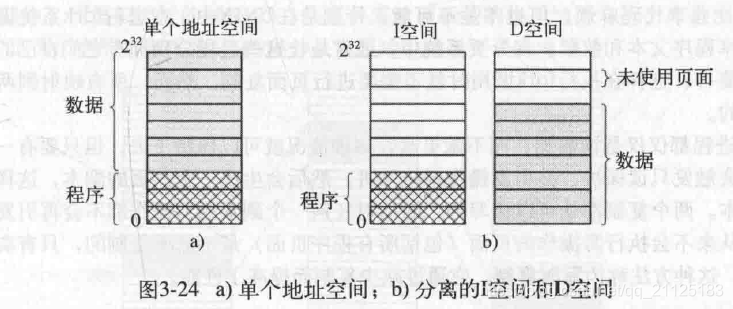
使用独立的指令地址空间跟数据地址空间,不仅有了更大的寻址范围,并且也有助于页面共享
共享页面
如果地址空间分离实现共享页面就会非常简单 通过写时复制
这需要对页表项做改造,需要记录该页面是否被共享,因为一个页面可能被多个进程使用,一个进程关闭了,不能随意将其的所有页面回收掉
共享库
共享库很适合使用数据共享,系统中其他程序可以复用共享库,共享库的数据只需在内存中加载一份
但需要注意的是共享库必须使用位置无关代码:只使用相对偏移量的代码,这样不同的进程调用时才不会出现问题
内存映射文件
把文件当做成一个内存中的大字符数组
清除策略
使用分页守护进程定时淘汰页面
虚拟内存接口
通过开放接口,使得不同进程之间可以拥有同一份内存,甚至不同计算机之前分布式共享内存
有关实现的问题
与分页有关的工作
- 创建一个新进程时:确定程序和数据大小,创建一个页表
- 进程执行时:重置MMU,刷新TLB,清除之前进程的痕迹
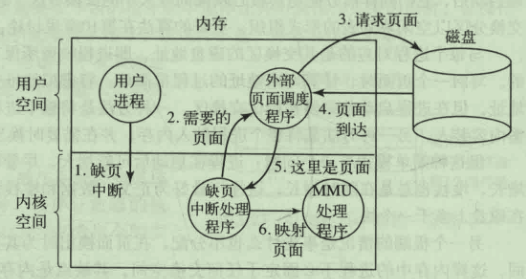
- 缺页中断时:确定是哪个虚拟地址发生了中断,读入所需页面,重新执行指令
- 进程退出时:释放页表、页面
缺页中断处理
- 陷入内核,保存当前指令的一些状态信息
- 尝试发现所需要的虚拟页面
- 如果虚拟页面的地址非法或者受到保护,则结束掉进程,否则就置换页框或者淘汰页面来置换
- 如果选择的页框脏了,则将该页写回磁盘,挂起该进程,进行上下文切换,直至磁盘传输结束,再将该进程切换回来
- 否则操作系统从磁盘读取该页到内存
- 恢复当前指令的状态信息,继续执行进程
指令备份
- 重启引起缺页中断的那条指令,这不是一件容易的事
由于指令是有状态,而且在执行缺页中断处理也会执行一些指令,这意味着需要记住指令的执行状态,一些CPU通过一个隐藏的寄存器来实现
锁定内存中的页面
- 锁住正在做IO操作的内存中的页面保证它不会被移出内存
后备存储
- linux中的swap
当需要将页面交换到磁盘时,静态的方式就是事前在交换区一一建立磁盘与页表的映射
动态的方式则是需要写到磁盘时,动态申请一块磁盘,需要在页表中记录磁盘的地址
整体架构设计
- MMU
- 缺页中断处理程序
- 页面调度程序
分段
如果使用一个一维的地址空间,将这个空间分为不同的区域,随着程序运行数据增加,区域之间就会发生重叠,表碰撞:动态增长的表会导致覆盖的问题
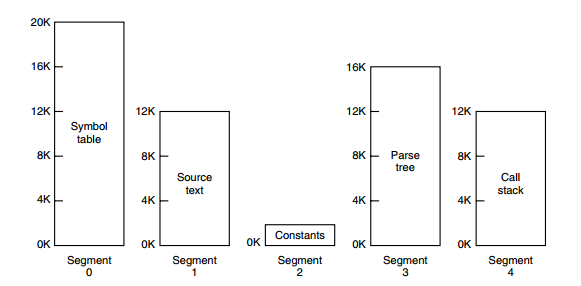
对于不同的段可以施加不同的限制,只读、不可执行
纯分段的实现
段页式
程序的地址空间划分成多个拥有独立地址空间的段,每个段上的地址空间划分成大小相同的页。这样既拥有分段系统的共享和保护,又拥有分页系统的虚拟内存功能
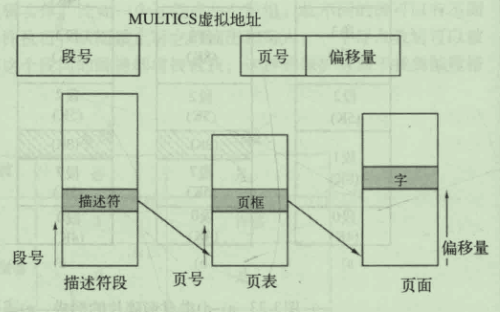
分段和分页结合:MULTICS
段(段号,段内地址(页号,偏移地址))
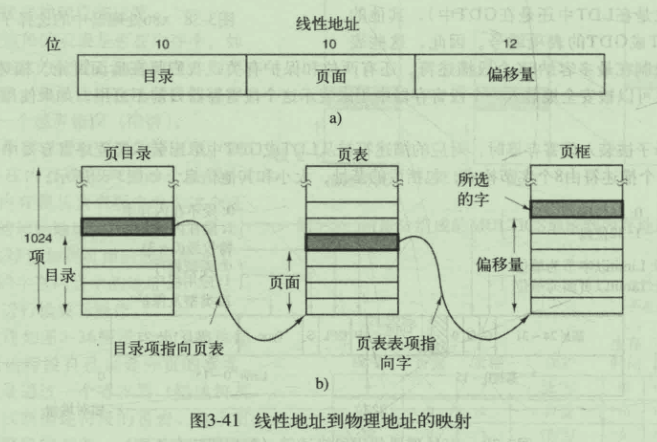
分段和分页结合:Intel x86
LDT与GDT 线性地址(目录,页面,偏移量)
分页与分段
| 对比 | 分页 | 分段 |
|---|---|---|
| 透明性 | 对程序员透明 | 需要程序员显示划分每个段 |
| 地址空间维度 | 一维地址 | 二维地址 |
| 大小可否改变 | 页大小不可改变 | 段大小可以动态改变 |
| 出现原因 | 分页用来实现虚拟内存,以获得更大的地址空间 | 分段是为了独立程序和数据并且有助于共享与保护 |
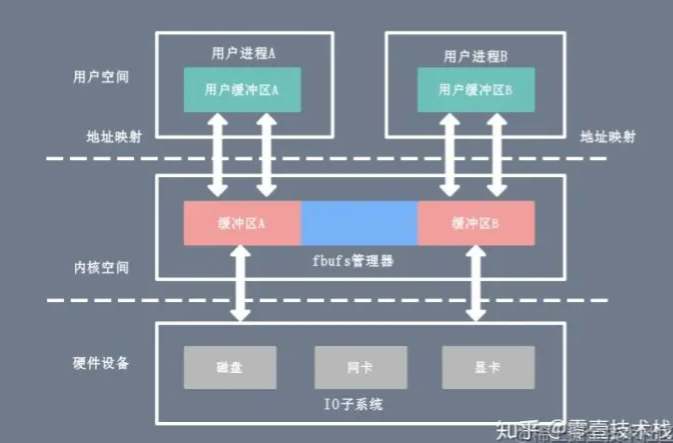
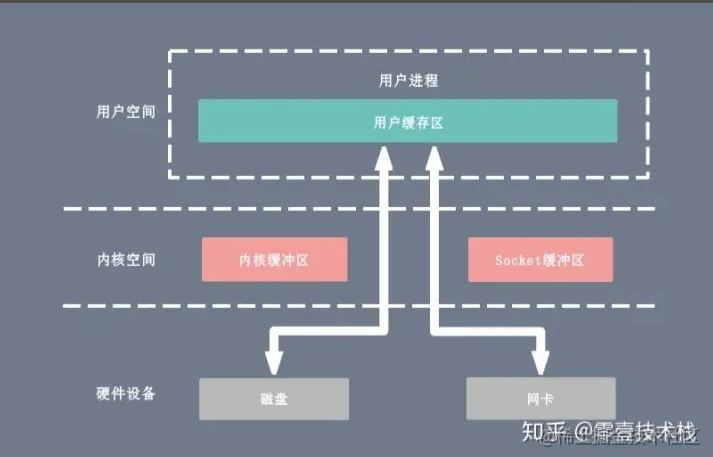
零拷贝
对IO设备的读写,不将IO设备的数据先复制到内核空间,然后再复制到用户空间,以此获得更高的读写性能
这就是由DMA所完成的
用户态直接IO
硬件上的数据直接拷贝至了用户空间,不经过内核空间
mmap+write
实现内核缓冲区与应用程序内存的共享,省去了将数据从内核读缓冲区(read buffer)拷贝到用户缓冲区(user buffer)的过程,然而内核读缓冲区(read buffer)仍需将数据到内核写缓冲区(socket buffer)
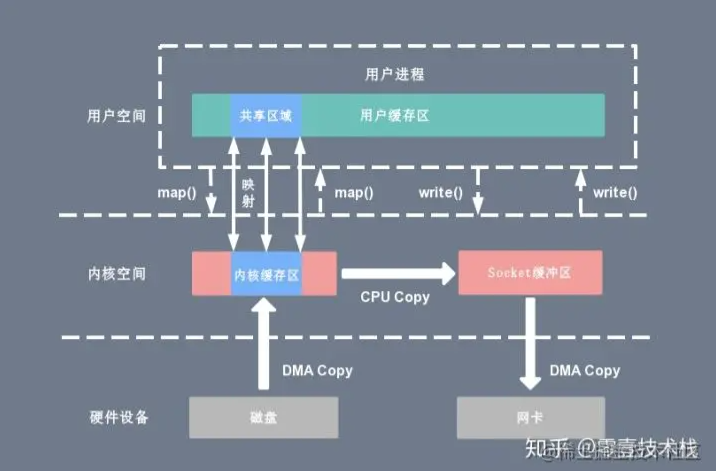
主要的用处是提高 I/O 性能,特别是针对大文件。对于小文件,内存映射文件反而会导致碎片空间的浪费
sendfile
#include ssize_t sendfile(int out_fd, int in_fd, off_t *offset, size_t count);
简化通过网络在两个通道之间进行的数据传输过程。sendfile 系统调用的引入,不仅减少了 CPU 拷贝的次数,还减少了上下文切换的次数
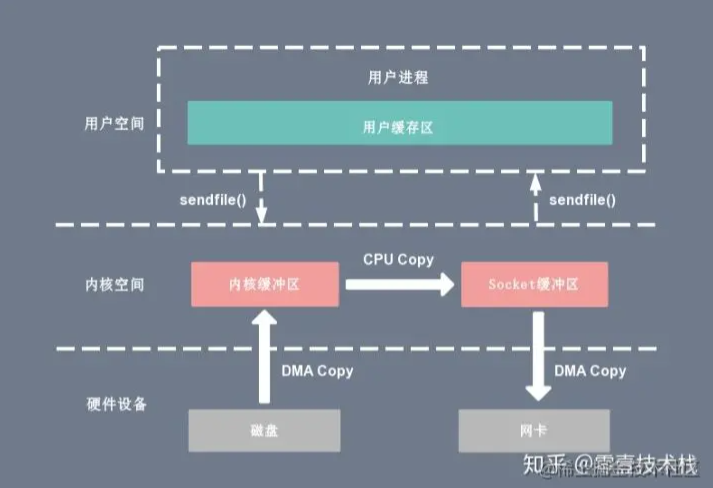
sendfile 存在的问题是用户程序不能对数据进行修改
sendfile+ DMA gather copy
将内核空间(kernel space)的读缓冲区(read buffer)中对应的数据描述信息(内存地址、地址偏移量)记录到相应的网络缓冲区( socket buffer)中,由 DMA 根据内存地址、地址偏移量将数据批量地从读缓冲区(read buffer)拷贝到网卡设备中
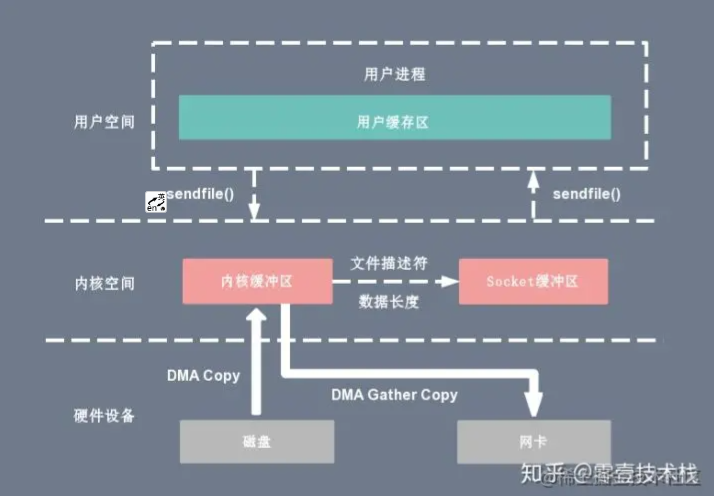
同样也不能对数据进行修改
splice
splice(fd_in, off_in, fd_out, off_out, len, flags);
跟sendfile很像
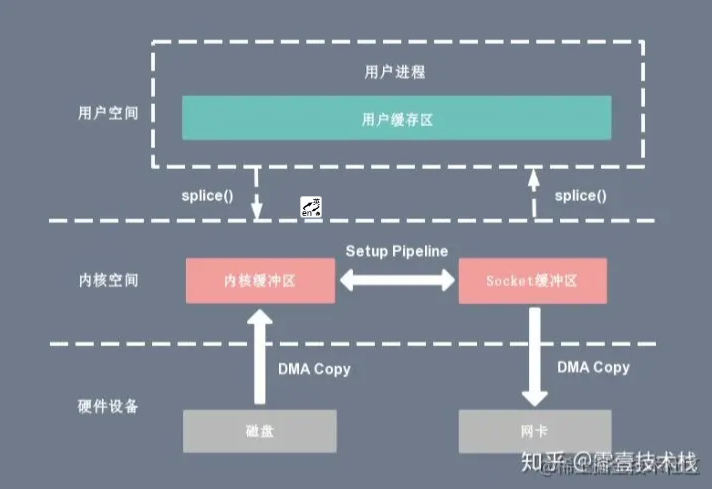
写时复制
当多个进程共享同一块数据时,如果其中一个进程需要对这份数据进行修改,那么就需要将其拷贝到自己的进程地址空间中
缓冲区共享
每个进程都维护着一个缓冲区池,这个缓冲区池能被同时映射到用户空间(user space)和内核态(kernel space),内核和用户共享这个缓冲区池,这样就避免了一系列的拷贝操作